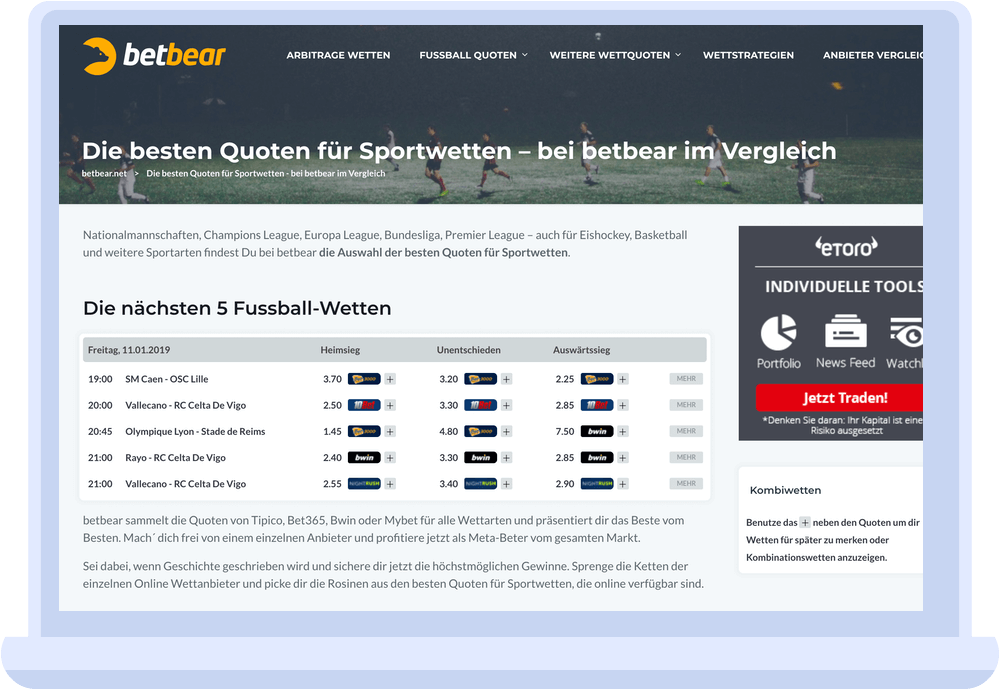
Sportwetten-Quotenvergleich
Wenn man mal „Sportwetten“ bei Google eingibt, wird man mit verschiedenen Anbietern regelrecht erschlagen. Ein Beispiel: Du willst auf das Spiel Bayern vs Dortmund in der ersten Bundesliga setzen – doch 10 Anbieter machen jeweils eine andere Quote. Selbst bei kleinen Wetteinsätzen sind Quotenunterschiede von 20-30% echtes Geld wert. Vor allem da es bei den meisten Anbietern relativ großzügige Erstanmelder-Boni gibt. Das Thema Sportwetten-Quotenvergleich ist also einerseits als Produkt interessant, aber auch technisch stellt es einige interessante Probleme
Integration von Wettanbieter-Quoten
Die Wettanbieter liefern die Quoten meist über sogenannte XML-Feeds aus. Das sind im wesentlichen strukturierte Dateien die mehrere Megabyte an Größe annehmen können. Schließlich bieten die meisten Anbieter viele verschiedene Sportarten und Ligen an. Die Daten der Buchmacher sind aber nicht nur groß, sondern auch unterschiedlich strukturiert. Häufig enthalten sie sogar Fehler. Es sind also zwei Schritte nötig um die Daten verwenden zu können: Homogenisierung und Arbitration.
Homogenisierung – Gleichmacherei der Daten
Jeder Buchmacher hat verschiedene Arten seine Daten zu kodieren. Allein die Namen der Vereine unterscheiden sich sehr stark. Ein Beispiel: Bayern München heißt bei einigen Anbietern „FC Bayern München“ und bei anderen wiederum nur „Bayern“. Bei ausländischen Anbietern wird es dann zum Beispiel auch „Bayern Munich“ oder – noch falscher – „Bayer Munich“. Man bekommt also im schlimmsten Fall von 10 verschiedenen Wettanbietern 10 verschiedene Namen für einzelne Vereine. Das Problem haben wir mit dem Anlegen und Pflegen von Namenslisten gelöst – sodass klar ist, dass alle Schreibweisen des FC Bayern München immer auf diesen „korrekten“ Namen abgebildet werden.
Die Homogenisierung ist natürlich auch abhängig vom Kontext. Teilweise werden Vereine nur mit dem Namen ihrer Stadt genannt, zB „Berlin“. Fußballfreunde wissen aber, dass es in Berlin mindestens 2 relevante Vereine gibt – Hertha BSC und Union. Man muss sich also immer im klaren drüber sein, ob man gerade über die Bundesliga oder die 2. Bundesliga redet. Das entwickelte System erledigt diese Aufgabe vollautomatisch.
Die Wettanbieter unterscheiden sich aber nicht nur in den Schreibweisen, sondern teilweise auch in den Zeiten. Jeder Buchmacher nutzt in seinem Feed eine andere Zeit – manche geben deutsche Zeiten, andere aber auch internationale Zeiten (UTC) an. Die Zeitzonen müssen dann entsprechend auch vollautomatisch homogenisiert werden.
Arbitration – wer hat Recht?
Unabhängig von den Vereinsnamen geben die Buchmacher auch manchmal völlig falsche Daten heraus. Ein Beispiel: Das (theoretische) DFB-Pokalspiel zwischen Bayern und Dortmund findet laut Spielplan am 26.4. 19:30 statt. Jetzt behaupten einige Buchmacher dass das Event tatsächlich am 26.4. 19:30 stattfindet, einige andere Buchmacher behaupten aber in ihren Daten felsenfest dass es am 27.4. 17:45 stattfindet. Was macht man jetzt? Es ist nicht möglich für jede Sportart eine Liste zu pflegen, wann welche Spiele stattfinden, da die Spielpläne nicht immer automatisch abzurufen sind.
Hier greift jetzt eine Prozess namens Arbitration – oder einfacher gesagt: Ein Mehrheitsentscheid. Wenn 3 Buchmacher behauptet das Spiel ist 19:30, dann wird der andere Buchmacher einfach überstimmt und die Daten entsprechend homogenisiert. In den allermeisten Fällen fällt den Buchmachern rechtzeitig auf, dass sie die falschen Daten verbreiten und dann korrigieren sie diese Fehler auch in ihrem Feed. Bis dahin ist durch den Arbitrationsprozess aber sichergestellt, dass wir auf betbear keine falschen Daten anzeigen.
Datenmengen effizient verarbeiten
Wenn man von 10 Buchmachern 30mb an Daten zieht, dann sind das schon 300MB – soviel wie 1000 Bücher. Aus informatischer Sicht ist das aber nicht viel – man muss die Daten nur effizient verarbeiten. Die Ziele sind:
- die Webseite muss schnell laden, also müssen die verarbeiteten Daten schnell zur Verfügung stehen
- Die Verarbeitung der XML-Feeds muss schnell erfolgen und wenig Arbeitsspeicher verwenden
- die Originaldaten sollen intakt bleiben, da sich der Verarbeitungsprozess ändern kann
Um diese drei Anforderungen zu erfolgen, nutzen wir einen dreistufigen Prozess:
- Die Daten werden von den Buchmachern angefragt und per SAX-Parsing ressourcenschonend verarbeitet. Danach werden sie in die Datenbank geschrieben, sodass wir sie nicht ständig neu anfragen müssen
- Die Rohdaten in der Datenbank werden verarbeiten – homogenisiert und arbitriert (siehe oben) – das Ergebnis der Verarbeitung wird wieder in die Datenbank geschrieben
- Die verarbeiteten Daten werden gebündelt um die häufigsten Anfragen schnell bedienen zu können. Zum Beispiel werden alle Bundesliga-Quoten, oder die Quoten der einzelnen Bundesligaspiele zusammengebündelt und in der Datenbank gespeichert. So muss man sich bei einem Seitenaufruf nur „schnell die Daten aus der Datenbank holen“ und nicht weiter verarbeiten.
Der Stack – moderne Web-Technologien
Das ganze betbear-System gliedert sich in mehrere Bestandteile, die auf unterschiedlichen Technologien basieren.
WordPress als Frontend und Webseite
Das Frontend, also die Webseite die der Endnutzer zu sehen bekommst, ist ein stinknormales WordPress. Dadurch dass wir die Seite SEO-Optimieren (mehr dazu unten), setzen wir der Einfachheit halber auf ein standardisiertes System. WordPress ist dafür ideal, da sich die Texter nicht umgewöhnen müssen.
Das WordPress-Theme wurde angepasst auf ein Design, welches von der Designagentur Koncepted entwickelt wurde. Außerdem wurden Komponenten programmiert, die ein Anzeigen der Quoten direkt in den WordPress-Seiten ermöglichen. Dazu gehört auch eine Möglichkeit, die Daten zu filtern und sich Quoten in einem Wettschein zu merken. WordPress selbst führt aber keine Datenverarbeitung durch – dazu dient das Backend.
Scala PlayFramework als das Backend
Das Backend ist mit der Java-nahen Programmiersprache Scala implementiert. Scala ist eine funktionale Programmiersprache, die gerade für das Abbilden von Prozessen und Datenverarbeitung gut ist. Die API des Backends ist eine asynchrone REST-API, welche alle Funktionen geschwindigkeitsoptimiert zur Verfügung stellt.
Alle Schritte für die oben beschriebene Datenverarbeitung werden vom Backend durchgeführt. Regelmäßig wiederkehrende Aufgaben werden als Jobs abgearbeitet. Automatische Tests sorgen dafür, dass die kritischen Komponenten fehlerfrei arbeiten.
MongoDB als Datenbank
Bei der Datenbank-Lösung setzten wir auf MongoDB, weil wir große Datenmengen, teilweise anormalisiert speichern wollten. Mongo ist dafür die perfekte Lösung, denn es ist schnell und auf heterogene Datenmengen spezialisiert.
Infrastruktur – bloß nichts selber hosten
Bei der Infrastruktur setzen wir ausschließlich auf Cloud-basierte Anwender. Das System soll selbstständig und vollautomatisiert laufen, demnach möchte man keinen eigenen Server betreiben den man ständig updaten muss. Zu diesem Zweck griffen wir auf verschiedene große Hosting Anbieter zurück:
WPEngine hostet das Frontend (WordPress). WPEngine ist ein auf WordPress spezialisierter Hosting-Anbieter der eine hohe Geschwindigkeit und einen extrem guten Service bietet. So müssen wir uns um nichts weiter kümmern.
Das Backend hosten wir auf Heroku – einem Cloud-Hosting Anbieter für Webanwendungen. Der Service skaliert selbstständig mit der Last die wir produzieren. Auch hier sparen wir uns den Aufwand der Serverwartung. Um auf Heroku zu deployen (neue Versionen auszuspielen) nutzen wir CircleCI, welches direkt auf unsere Versionsverwaltung BitBucket zurückgreift.
Unsere MongoDB-Datenbank hosten wir bei MongoDBs eigenem Hosting-Service Atlas. Eine Datenbank zu warten ist normalerweise ein riesiger Aufwand. Den sparen wir uns.
Fehlermeldungen die von der Applikation ausgegeben werden, sammeln wir bei Sentry.io – so werden wir automatisch per E-Mail informiert, wenn irgendwas kaputt geht.
Unterm Strich kann man sagen, dass wir alle aufwändigen und nervigen Prozesse an externe Anbieter abgegeben haben. Eigentlich genau so, wie es bei modernen Start-Ups üblich ist.
SEO-Optimierung
SEO-Optimierung ist natürlich ein wichtiges Thema, schließlich wollen wir ja, dass die Seite am Ende erfolgreich funktioniert. Teil der Optimierung ist natürlich die technische Optimierung – also Geschwindigkeit, Meta-Daten und solche Sachen wie Structured Data. Wirklich erfolgreich wird die Seite aber nur durch gute Inhalte, gute Texte, Bilder etc. Wie das richtig geht fragst du am Besten mal den SEO nerd, und wenn du Entwicklungsleistungen brauchst, weil du ein ähnlich komplexes Projekt auf die Beine stellen willst – frag uns.